MULTI-TIER PLUGIN EVAL CLI
EVOLVE
Evaluate coding-agent plugins, across every model.
Evolve validates plugin structure, checks whether skills trigger on the right prompts, and runs behavioral eval suites in throwaway workspaces — across Anthropic, OpenAI, Google, Cursor, Copilot and Antigravity. It writes committed Markdown + JSON rollups for review and CI, all from one Go binary.
$ brew install --cask bitwise-media-group/tap/evolve
$ evolve run all
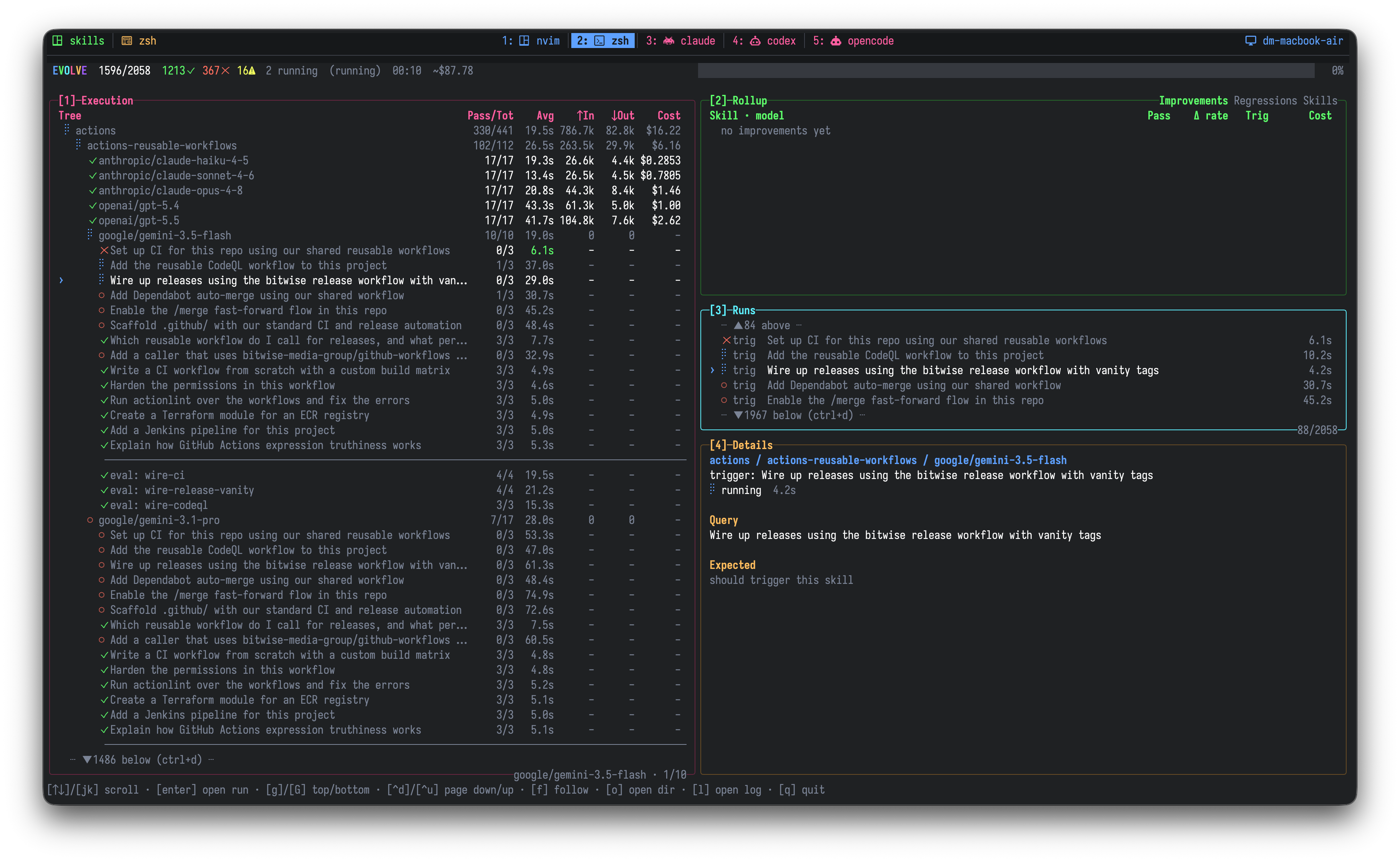
The Evolve live dashboard — [1] execution tree · [2] rollup · [3] runs · [4] details, streaming as agents finish.
2,058EVALS IN SUITE
1,213 ✓PASSED
367 ✕FAILED
$87.78SPENT THIS RUN
// WHAT EVOLVE DOES
One CLI for evaluating coding-agent plugins across every model.
Multi-tier by design
Static checks, trigger-accuracy evals and behavioral evals in one pass.
evolve run all runs check → triggers → evals → report.
Every model
Anthropic, OpenAI, Google, Cursor, Copilot and Antigravity — each driven through its own harness
CLI. Pick a single model or a whole provider with --model.
Trigger accuracy
Tier 1 runs each trigger prompt several times and records whether the expected skill activated — scored per model.
Behavioral evals
Tier 2 runs behavioral cases in throwaway workspaces, graded by deterministic assertions — files, regexes, commands — and an optional LLM judge.
Deterministic reports
Committed Markdown + JSON rollups, deterministic to the byte. --strict and
report --check gate CI on pass-rate thresholds.
>_
One Go binary
Install once, run against any plugin repo. Auto-detects marketplace, multi and single layouts — terminal-native, no services.
HARNESSES
claude
codex
gemini
copilot
agy
PROVIDERS
anthropic
openai
google
cursor
// CONFIGURE ONCE
Configure once in a
.evolve.yaml
at your repo root.
# .evolve.yaml — optional, at the repo root layout: marketplace models: - anthropic - cursor/composer-2.5 harnesses: - claude - codex results_format: json max_turns: 12 stale_results: keep report: thresholds: triggers_min_pass_rate: 0.8 evals_min_pass_rate: 0.9
// THREE COMMANDS TO YOUR FIRST RUN
01
Install
Homebrew cask, or build from source with go install.
$ brew install --cask bitwise-media-group/tap/evolve
02
Check
Confirm harnesses, credentials and counting APIs.
$ evolve doctor
03
Run
Launch the run and watch the TUI stream live.
$ evolve run all